mysql5.7中type的类型达到了14种之多,这里只记录和理解最重要且经常遇见的六种类型,它们分别是all,index,range,ref,eq_ref,const。从左到右,它们的效率依次是增强的
mysql explain功能中展示各种信息的解释:
1 | id:优化器选定的执行计划中查询的序列号。 |
用小的数据量驱动大的结果集
索引失效问题
底层btree机制
首先抛个问题,MySQL的索引为何用树而不是其他数据结构如hash,hash的读和写都是O(1),而树的话查询和插入都是O(log(n))?
答:因为索引设计成树,是和SQL需求相关的,如果单独只查询某条数据,自然是hash算法快,但是我们平常用的查询往往不是只查询单条数据,而是order by,group by,< >这种排序查询,遇到这种情况,hash就会退化成O(n),而树因为它的有序性依然保持O(log(n))高效率。
那为何用的是B+树呢?这就得比较B树,B+树与红黑树的区别了。
- B+树的非叶子节点只保存索引,不保存行记录。而B树叶子节点和非叶子节点都存储索引和行记录,这样的话,同样的空间,B+树能存储更多的索引。这就意味着同样的数据,B+树比B树更”矮胖“,减少IO次数。
- 查询的时候,由于B树叶子节点和非叶子节点都存在行记录,也就是是说,B树查询其实是不稳定的(好的时候,只查根节点,坏的时候,查到叶子节点)。而B+树查询最终必须到叶子节点,查询销量稳定。
- B树范围查询只能通过中序遍历查询来定位最小和最大值,而B+树通过链表就能实现,查询更方便。
综合起来:B+树比B树优势有三个:1.IO次数更少;2.查询性能更稳定;3.范围查询简便。
InnoDB一棵B+树可以存放多少行数据?这个问题的简单回答是:约2千万
那如何计算呢?
首先我假设每行记录为1k,
首先假设树高为2,那么根节点存储的指针对应每个叶子节点。也就是说,最大的话,有多少个指针就有多少个叶子节点。
这棵B+树存储的总行数=根节点指针树每个叶子节点的行记录树。
那么根节点能存储多少指针呢?
InnoDB最小单位为页,一页为16k,我们假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节,那么一页的总指针树为16k/(8+6) = 1170。
每个指针对应1页,假设每行记录为1k(实际上现在很多互联网业务数据记录大小通常就是1K左右),那么一页大概能存16条行记录。
所以这棵B+树总行数为:117016 = 18720
三层的话,总指针数为1170 1170,故总行数为1170 1170*16=21902400
所以当单表数据超过千万级别后,就得考虑分表了,否则B+树的层级可能会超过3级,造成查询效率下降。
聚簇索引和非聚簇索引
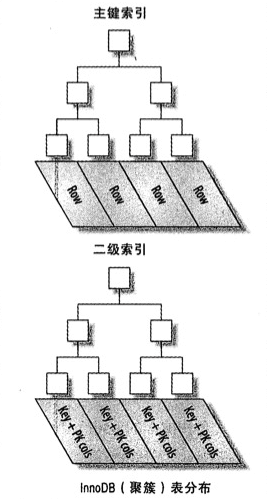
数据库表的索引从数据存储方式上可以分为聚簇索引和非聚簇索引(又叫二级索引)两种
聚簇索引的优点
聚簇索引将索引和数据行保存在同一个B-Tree中,查询通过聚簇索引可以直接获取数据,相比非聚簇索引需要第二次查询(非覆盖索引的情况下)效率要高。
聚簇索引对于范围查询的效率很高,因为其数据是按照大小排列的,
聚簇索引的缺点
聚簇索引的更新代价比较高,如果更新了行的聚簇索引列,就需要将数据移动到相应的位置。这可能因为要插入的页已满而导致“页分裂”。
插入速度严重依赖于插入顺序,按照主键进行插入的速度是加载数据到Innodb中的最快方式。如果不是按照主键插入,最好在加载完成后使用OPTIMIZE TABLE命令重新组织一下表。
聚簇索引在插入新行和更新主键时,可能导致“页分裂”问题。
聚簇索引可能导致全表扫描速度变慢,因为可能需要加载物理上相隔较远的页到内存中(需要耗时的磁盘寻道操作)。
非聚簇索引
非聚簇索引,又叫二级索引。二级索引的叶子节点中保存的不是指向行的物理指针,而是行的主键值。当通过二级索引查找行,存储引擎需要在二级索引中找到相应的叶子节点,获得行的主键值,然后使用主键去聚簇索引中查找数据行,这需要两次B-Tree查找。
主键和唯一索引都要求值唯一,但是它们还是有区别的:
1.主键是一种约束,唯一索引是一种索引;
2.一张表只能有一个主键,但可以创建多个唯一索引;
3.主键创建后一定包含一个唯一索引,唯一索引并一定是主键;
4.主键不能为null,唯一索引可以为null;
5.主键可以做为外键,唯一索引不行;
全文索引的版本、存储引擎、数据类型的支持情况
MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引;
MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引;
只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
使用全文索引
和常用的模糊匹配使用 like + % 不同,全文索引有自己的语法格式,使用 match 和 against 关键字,比如
select * from fulltext_test where match(content,tag) against('xxx xxx');
注意: match() 函数中指定的列必须和全文索引中指定的列完全相同,否则就会报错,无法使用全文索引,这是因为全文索引不会记录关键字来自哪一列。如果想要对某一列使用全文索引,请单独为该列创建全文索引。
mysql强制索引和禁止某个索引
mysql强制使用索引:force index(索引名或者主键PRI)
1 | select * from table force index(PRI) limit 2;(强制使用主键) |
mysql禁止某个索引:ignore index(索引名或者主键PRI)
1 | select * from table ignore index(PRI) limit 2;(禁止使用主键) |
MySQL索引分类
MySQL索引分为普通索引、唯一索引、主键索引、组合索引、全文索引。索引不会包含有null值的列,索引项可以为null(唯一索引、组合索引等),但是只要列中有null值就不会被包含在索引中。
(1)普通索引:create index index_name on table(column);
或者创建表时指定,create table(..., index index_name column);
(2)唯一索引:类似普通索引,索引列的值必须唯一(可以为空,这点和主键索引不同)
create unique index index_name on table(column);或者创建表时指定unique index_name column
(3)主键索引:特殊的唯一索引,不允许为空,只能有一个,一般是在建表时指定primary key(column)
(4)组合索引:在多个字段上创建索引,遵循最左前缀原则。alter table t add index index_name(a,b,c);
(5)全文索引:主要用来查找文本中的关键字,不是直接与索引中的值相比较,像是一个搜索引擎,配合match against使用,现在只有char,varchar,text上可以创建全文索引。在数据量较大时,先将数据放在一张没有全文索引的表里,然后再利用create index创建全文索引,比先生成全文索引再插入数据快很多。
何时使用索引
MySQL每次查询只使用一个索引。与其说是“数据库查询只能用到一个索引”,倒不如说,和全表扫描比起来,去分析两个索引B+树更加耗费时间。所以where A=a and B=b这种查询使用(A,B)的组合索引最佳,B+树根据(A,B)来排序。
(1)主键,unique字段;
(2)和其他表做连接的字段需要加索引;
(3)在where里使用>,≥,=,<,≤,is null和between等字段;
(4)使用不以通配符开始的like,where A like ‘China%’;
(5)聚集函数MIN(),MAX()中的字段;
(6)order by和group by字段;
何时不使用索引
(1)表记录太少;
(2)数据重复且分布平均的字段(只有很少数据值的列);
(3)经常插入、删除、修改的表要减少索引;
(4)text,image等类型不应该建立索引,这些列的数据量大(假如text前10个字符唯一,也可以对text前10个字符建立索引);
(5)MySQL能估计出全表扫描比使用索引更快时,不使用索引;
索引何时失效
(1)组合索引未使用最左前缀,例如组合索引(A,B),where B=b不会使用索引;
(2)like未使用最左前缀,where A like ‘%China’;
(3)搜索一个索引而在另一个索引上做order by,where A=a order by B,只使用A上的索引,因为查询只使用一个索引 ;
(4)or会使索引失效。如果查询字段相同,也可以使用索引。例如where A=a1 or A=a2(生效),where A=a or B=b(失效)
(5)如果列类型是字符串,要使用引号。例如where A=’China’,否则索引失效(会进行类型转换);
(6)在索引列上的操作,函数(upper()等)、or、!=(<>)、not in等;